[Blog] [Paper] [Model card] [Colab example]
Whisper is a general-purpose speech recognition model. It is trained on a large dataset of diverse audio and is also a multi-task model that can perform multilingual speech recognition as well as speech translation and language identification.
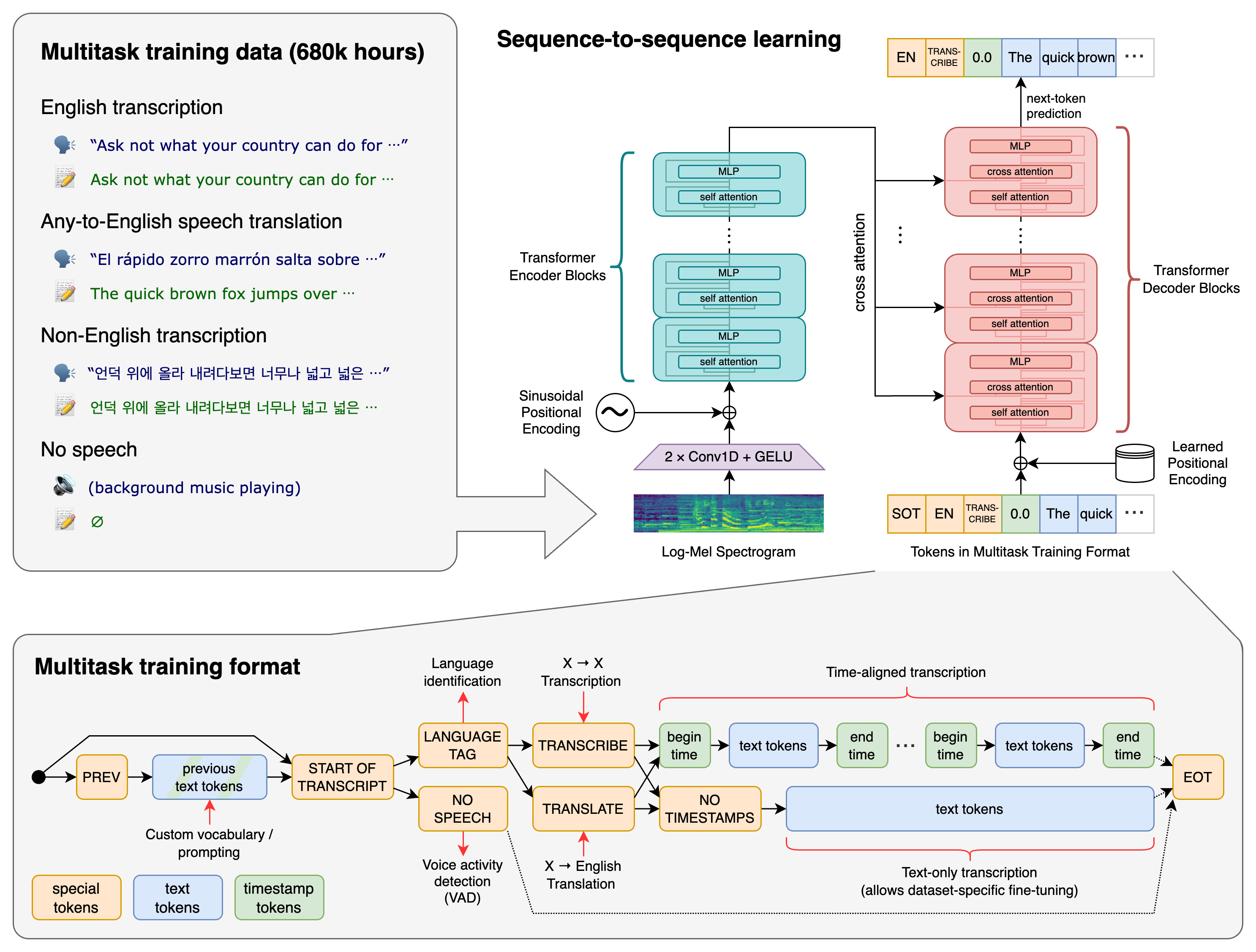
A Transformer sequence-to-sequence model is trained on various speech processing tasks, including multilingual speech recognition, speech translation, spoken language identification, and voice activity detection. All of these tasks are jointly represented as a sequence of tokens to be predicted by the decoder, allowing for a single model to replace many different stages of a traditional speech processing pipeline. The multitask training format uses a set of special tokens that serve as task specifiers or classification targets.
We used Python 3.8 and PyTorch (gpu) to finetune models
pip install datasets
pip install transformers
pip install librosa
pip install evaluate
pip install jiwer
pip install gradio
[Key link1] [Key link2] [Key link3]
Step 1: Getting familiar with the flow of the finetune whisper model by using the commonvoice corpus
Step 2: Rewrite the entire finetune module (mainly pre-processing of the Irish corpus and how to put it into pytorch, mainly building Dataset subclasses)
Step 3: Build a mini dataset and divide the train dataset and test dataset to check the correctness of the whole finetune process
Step 4: How to do a finetune training on the tokenizer, mainly because the existing tokenizer in whisper does not support Irish
[[link1]](https://github.com/facebookresearch/fairseq/tree/main/examples/mbart)
Step 5: How to find the most suitable training parameters for the Irish speech
Step 6: The order of finetune, which parameter should be adjusted first, can it be adjusted separately?
Step 7: Consider optimizing Adam or Adafactor in training
Step 8: Use Data Enhancement to Boost Results
Step 9: Analyze the sentences that identify errors and count the different types of errors before considering other options to improve the model