Interested in using this scraper? Get it here: Indeed Jobs Scraper
Watch the live demo here: Indeed scraper demo
The "Indeed jobs scraper" actor allows you to extract job listings and associated details from indeed.com job search website. It provides a simple and efficient way to gather job data for analysis, research, lead generation or other purposes.
The actor utilizes web scraping techniques to navigate through search result pages, extract job listings, and retrieve relevant information such as job titles, companies, locations, salaries, and more. It supports various filters and options to customize the scraping process and retrieve specific job data based on your requirements.
There are two versions:
Scrapes job data: The scraper will query the Indeed search page with your query parameters and extract the job data directly from the search results.
Scrapes Jobs Data with company details: The scraper will crawl the Indeed search pages with your query parameters, then send a request to each individual company page to scrape all the company details data from the page.
This Indeed spider uses Apify proxy as the proxy solution. Apify has a free plan that gives you free credits worth $5 per month which makes it ideal for the development phase, but can be easily scaled up to millions of pages per month if needs be.
You can sign up for a free account here
Here are some use cases for an Indeed jobs scraper:
-
Job Market Research: Use an Indeed scraper to collect job postings in a specific industry or location. This data can be analyzed to identify trends, such as job demand, salary ranges, and skill requirements, which can inform business strategies or career decisions.
-
Competitor Analysis: Monitor your competitors' job postings on Indeed to gain insights into their hiring strategies and the types of positions they are actively recruiting for. This can help you stay competitive in the job market.
-
Company Research: Scraper can be used to gather data on companies posting job listings on Indeed, including information about their industry, location, and hiring patterns. This data can be valuable for business development and partnership opportunities.
-
Salary Benchmarking: Collect salary information from job postings to understand the average compensation for specific roles in different regions. This data can be used to benchmark your own salary structure or negotiate better compensation.
-
Location-Based Insights: Analyze job postings in different geographical locations to identify areas with high demand for specific skills or industries. This information can guide decisions about where to expand or relocate a business.
-
Lead Generation: Scraping job postings for contact information (where available) can be used for lead generation. This is particularly useful for B2B companies looking to connect with potential clients or partners in specific industries or roles.
-
CRM Enrichment: If you have a CRM (Customer Relationship Management) system, you can use the scraper to enrich your existing contacts with information about their current job positions, companies, and industries. This helps you maintain up-to-date and relevant customer profiles.
-
Marketplace Insights: Analyze job postings to understand the demand for certain skills or certifications in the job market. This information can be valuable for educational institutions and training providers to tailor their programs to meet industry needs.
-
Career Planning: Individuals can use an Indeed scraper to track job openings in their desired industry or location. This helps with career planning and staying informed about job opportunities that match their skills and interests.
-
Content Creation: Bloggers, journalists, or researchers can use scraped job data to create reports, articles, or blog posts about employment trends, job market changes, or emerging industries.
-
Consulting Services: Offer consulting services to businesses based on the insights gained from scraping Indeed data. Help companies optimize their hiring processes, identify market gaps, or make informed decisions about expansion and talent acquisition.
- Go to indeed.com and search for jobs with filters such as job title, company name, and location
- Copy the URL from the address bar. This is the Search URL you need to pass to the scraper
- Go to Indeed scraper on the Apify platform
- Click the Try for free button
- Insert the search URL you copied in step 2
- Enter number of jobs needed
- Select a residential proxy of your country
- Click the Start button
- When the run has finished, click the Export button
- View and download your data
Here is are the available options of this scraper:
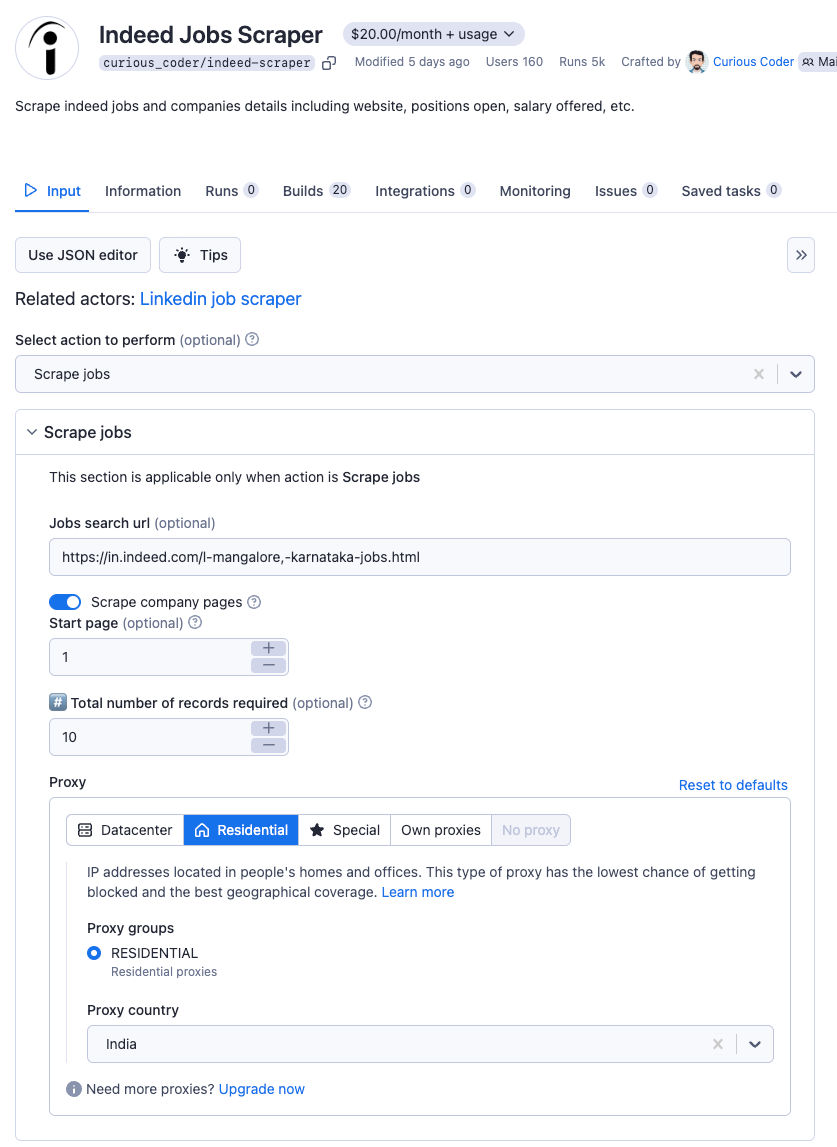
You can use Make to integrate apollo leads to any other SaaS platform by designing your own automation flows.
If you want to extract more information from job description using ai (for eg: skills, benefits, contact info, websites, companies, etc) try GPT AI Assistant
You can download the dataset extracted by indeed scraper in various formats such as JSON, HTML, CSV, or Excel.
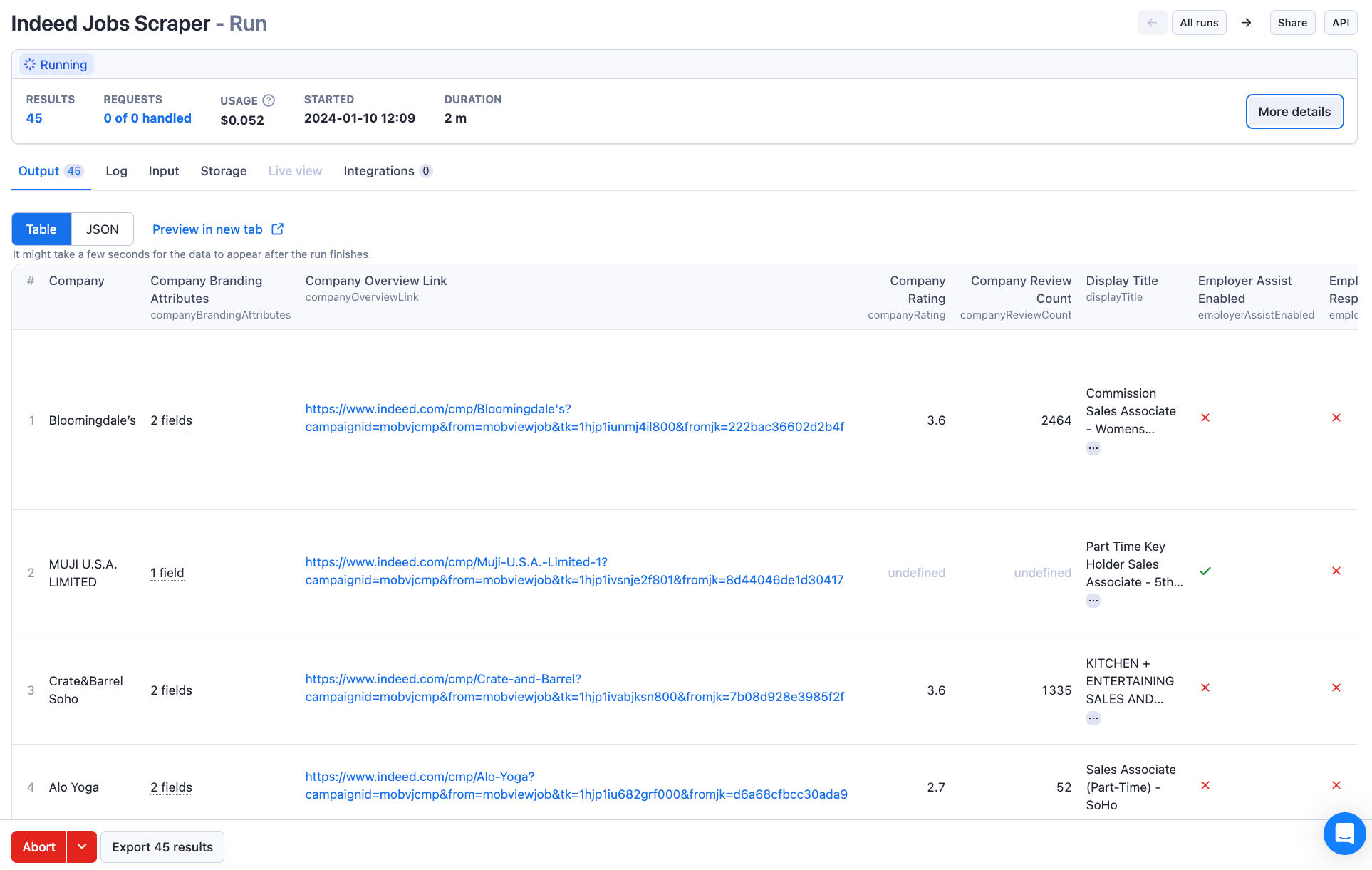
This documentation provides an overview and description of the fields present in the given JSON data obtained from indeed.com.
company: The name of the company offering the job.companyBrandingAttributes: Additional branding attributes of the company.headerImageUrl: The URL of the header image associated with the company.logoUrl: The URL of the company's logo image.
companyOverviewLink: The URL to the company's overview page.companyRating: The company's rating on Indeed.companyWebsite: The link to company's website.companyReviewCount: The number of reviews for the company.displayTitle: The displayed title of the job.dradisJob: A boolean value indicating if it is a DRADIS job.employerAssistEnabled: A boolean value indicating if employer assist is enabled.employerResponsive: A boolean value indicating if the employer is responsive.encryptedFccompanyId: The encrypted ID of the FCC company.expired: A boolean value indicating if the job posting has expired.extractedSalary: The extracted salary information.max: The maximum salary value.min: The minimum salary value.type: The type of salary (e.g., yearly, monthly).
fccompanyId: The FCC company ID.featuredCompanyAttributes: Additional attributes of the featured company.featuredEmployer: A boolean value indicating if the employer is featured.featuredEmployerCandidate: A boolean value indicating if the employer is featured for the candidate.feedId: The ID of the job feed.formattedLocation: The formatted location of the job.formattedRelativeTime: The relative time when the job was posted.hideMetaData: A boolean value indicating if metadata is hidden.highVolumeHiringModel: The high volume hiring model information.highVolumeHiring: A boolean value indicating if high volume hiring is enabled.
hiringEventJob: A boolean value indicating if it is a hiring event job.homepageJobFeedSectionId: The ID of the job feed section on the homepage.indeedApplyEnabled: A boolean value indicating if Indeed Apply is enabled.indeedApplyable: A boolean value indicating if the job is Indeed Applyable.isJobVisited: A boolean value indicating if the job has been visited.isMobileThirdPartyApplyable: A boolean value indicating if third-party mobile application is available.isNoResumeJob: A boolean value indicating if the job does not require a resume.isSubsidiaryJob: A boolean value indicating if it is a subsidiary job.jobCardRequirementsModel: The model containing information about job card requirements.additionalRequirementsCount: The count of additional job requirements.requirementsHeaderShown: A boolean value indicating if the requirements header is shown
jobLocationCity: The city where the job is located.jobLocationState: The state where the job is located.jobTypes: An array of job types associated with the job.jobkey: The key associated with the job.jsiEnabled: A boolean value indicating if JSI (Job Spotter Integration) is enabled.link: The URL link to the job posting.locationCount: The count of locations associated with the job.mobtk: The mobile token associated with the job.newJob: A boolean value indicating if it is a new job posting.normTitle: The normalized title of the job.openInterviewsInterviewsOnTheSpot: A boolean value indicating if interviews are conducted on the spot for open interviews.openInterviewsJob: A boolean value indicating if it is an open interviews job.openInterviewsOffersOnTheSpot: A boolean value indicating if offers are made on the spot for open interviews.openInterviewsPhoneJob: A boolean value indicating if it is a phone job for open interviews.overrideIndeedApplyText: A boolean value indicating if the Indeed Apply text is overridden.preciseLocationModel: The model containing information about the precise location.obfuscateLocation: A boolean value indicating if the location should be obfuscated.overrideJCMPreciseLocationModel: A boolean value indicating if the JCMPreciseLocationModel is overridden.
pubDate: The publication date of the job posting.rankingScoresModel: The model containing ranking scores for the job.bid: The bid score.eApply: The eApply score.eQualified: The eQualified score.
redirectToThirdPartySite: A boolean value indicating if the user should be redirected to a third-party site.remoteLocation: A boolean value indicating if the job is a remote location.remoteWorkModel: The model containing information about remote work.inlineText: A boolean value indicating if the text should be displayed inline.type: The type of remote work (e.g., REMOTE_HYBRID).
resumeMatch: A boolean value indicating if the user's resume is a match for the job.salarySnippet: The snippet of salary information.currency: The currency of the salary.salaryTextFormatted: A boolean value indicating if the salary text is formatted.source: The source of the salary information.text: The text of the salary information.
screenerQuestionsURL: The URL for screener questions.showAttainabilityBadge: A boolean value indicating if the attainability badge should be shown.showCommutePromo: A boolean value indicating if the commute promotion should be shown.showEarlyApply: A boolean value indicating if the early apply option should be shown.showJobType: A boolean value indicating if the job type should be shown.showRelativeDate: A boolean value indicating if the relative date should be shown.showSponsoredLabel: A boolean value indicating if the sponsored label should be shown.showStrongerAppliedLabel: A boolean value indicating if the stronger applied label should be shown.smartFillEnabled: A boolean value indicating if smart fill is enabled.smbD2iEnabled: A boolean value indicating if SMB (Small and Medium-sized Business) D2I is enabled.snippet: The snippet of the job description.sourceId: The ID of the data source.sponsored: A boolean value indicating if the job posting is sponsored.taxoAttributes: The taxonomy attributes associated with the job.taxoAttributesDisplayLimit: The limit of taxonomy attributes to display.taxoLogAttributes: The taxonomy log attributes associated with the job.taxonomyAttributes: The taxonomy attributes associated with the job.attributes: The attributes of the taxonomy.label: The label of the attribute.suid: The SUID (System Unique Identifier) of the attribute.
label: The label of the taxonomy.
tier: The tier information associated with the job.matchedPreferences: The matched preferences within the tier.longMatchedPreferences: An array of long matched preferences.stringMatchedPreferences: An array of string matched preferences.
type: The type of the tier.
title: The title of the job.translatedAttributes: The translated attributes of the job.translatedCmiJobTags: The translated CMI (Career Management Integration) job tags.truncatedCompany: The truncated name of the company.urgentlyHiring: A boolean value indicating if the employer is urgently hiring.viewJobLink: The link to view the job details.vjFeaturedEmployerCandidate: A boolean value indicating if the employer is featured for the candidate on VJ (View Job) page.workplaceInsights: Insights about the workplace associated with the job.
The actor stores results in a dataset. You can export data in various formats such as CSV, JSON, XLS, etc. You can scrape and access data on demand using API. For more information, Go to Indeed jobs scraper API integration page
To use this scraper you need to pay $20 per month fixed cost to the developer and you should have an Apify subscription which starts from $49/mo prepaid usage credits. Based on historical data our scraper costs an average of $0.73 per thousand jobs scraped as usage credits. Based on above data, you can scrape upto 67,000 jobs per month with starter plan
Our scrapers are ethical and do not extract any private user data, such as email addresses, gender, or location. They only extract what the user has chosen to share publicly. We therefore believe that our scrapers, when used for ethical purposes by Apify users, are safe. However, you should be aware that your results could contain personal data. Personal data is protected by the GDPR in the European Union and by other regulations around the world. You should not scrape personal data unless you have a legitimate reason to do so. If you're unsure whether your reason is legitimate, consult your lawyers. You can also read our blog post on the legality of web scraping
We’re always working on improving the performance of our Actors. So if you’ve got any technical feedback for Indeed Scraper or simply found a bug, please create an issue on the actor’s Issues tab in Apify Console.