| theme | layout | lineNumbers | themeConfig | title | info | class | highlighter | drawings | mdc | hideInToc | favicon | titleTemplate | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
slidev-theme-dataroots |
intro |
false |
|
MLOps |
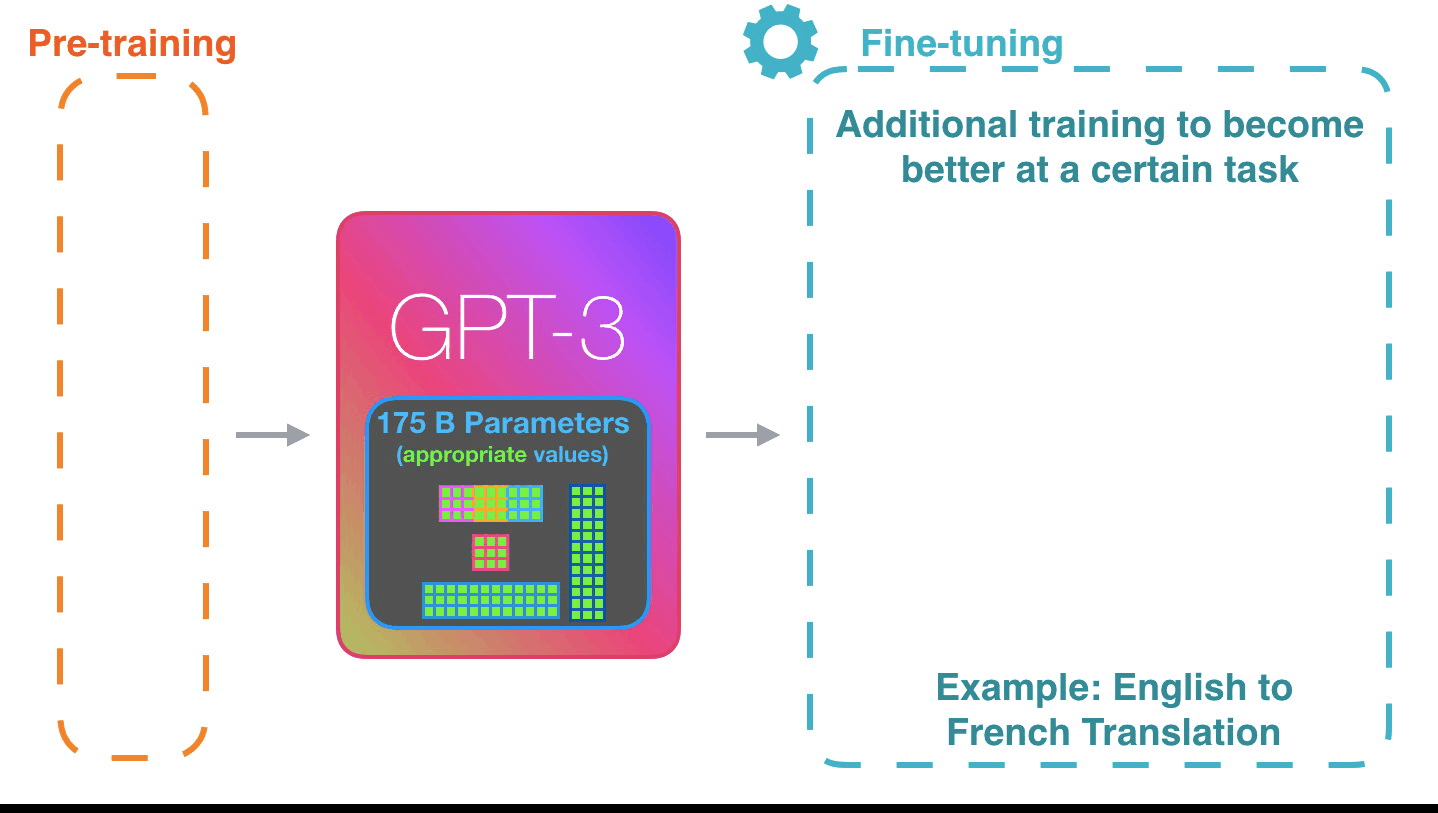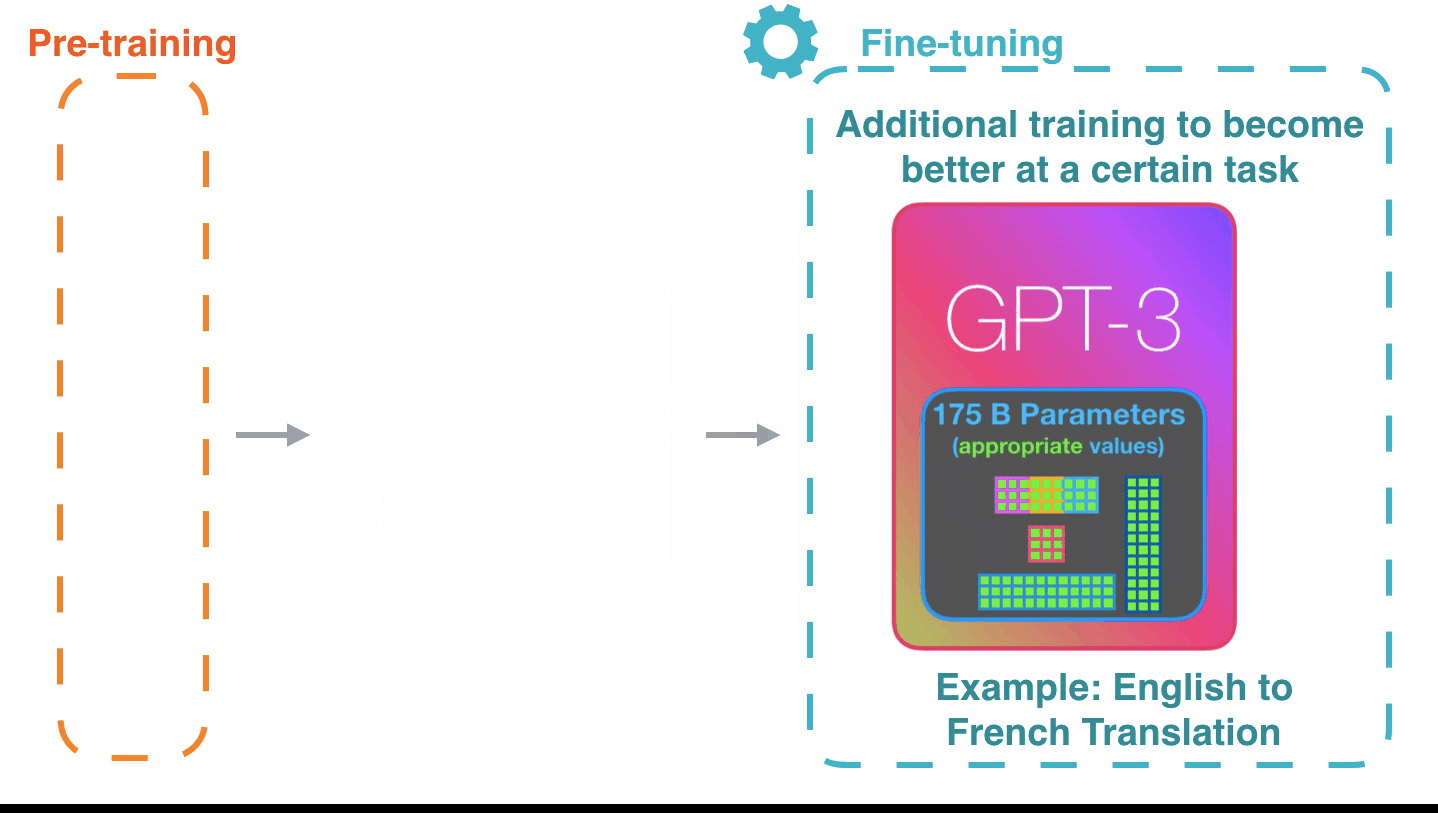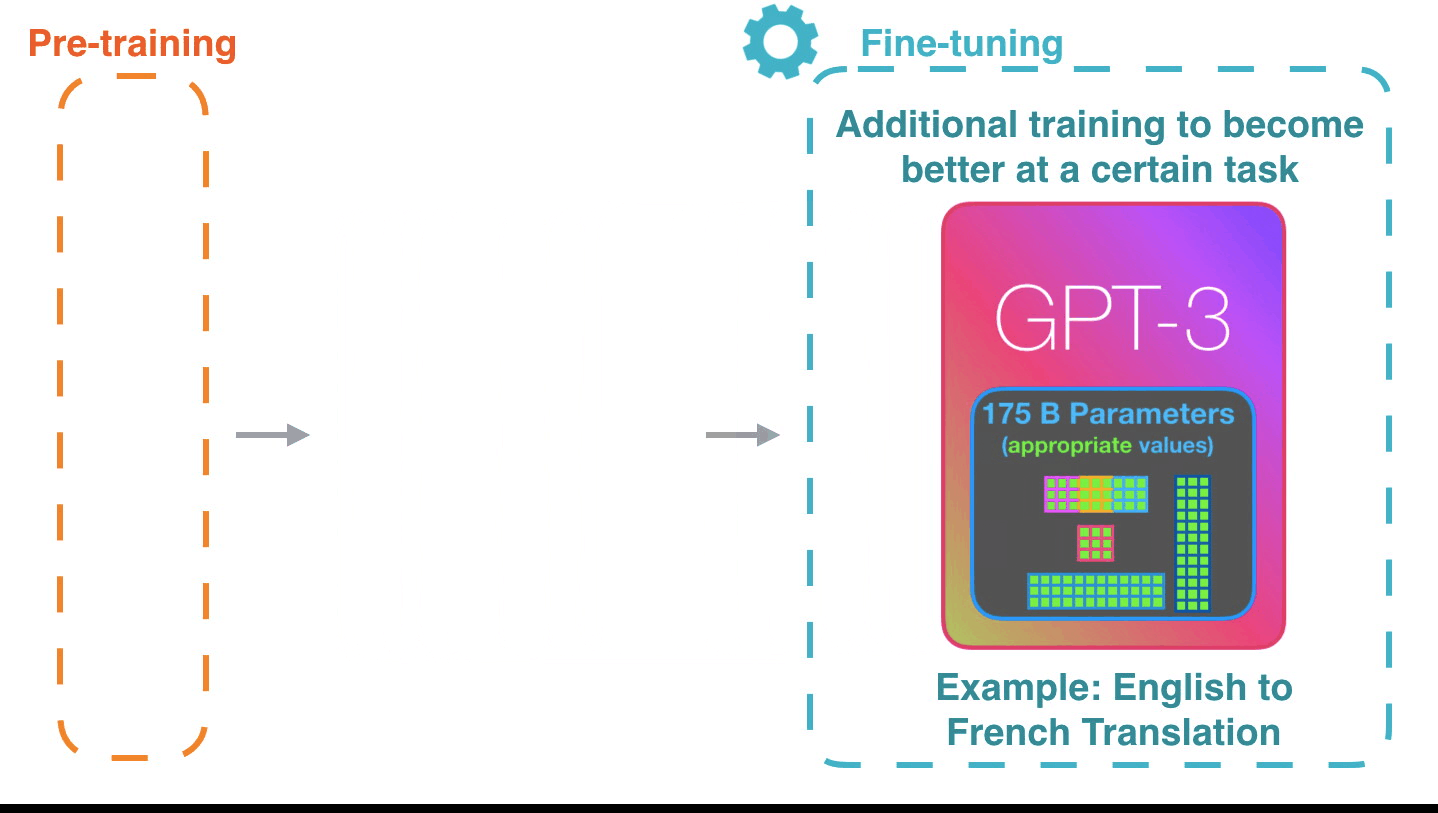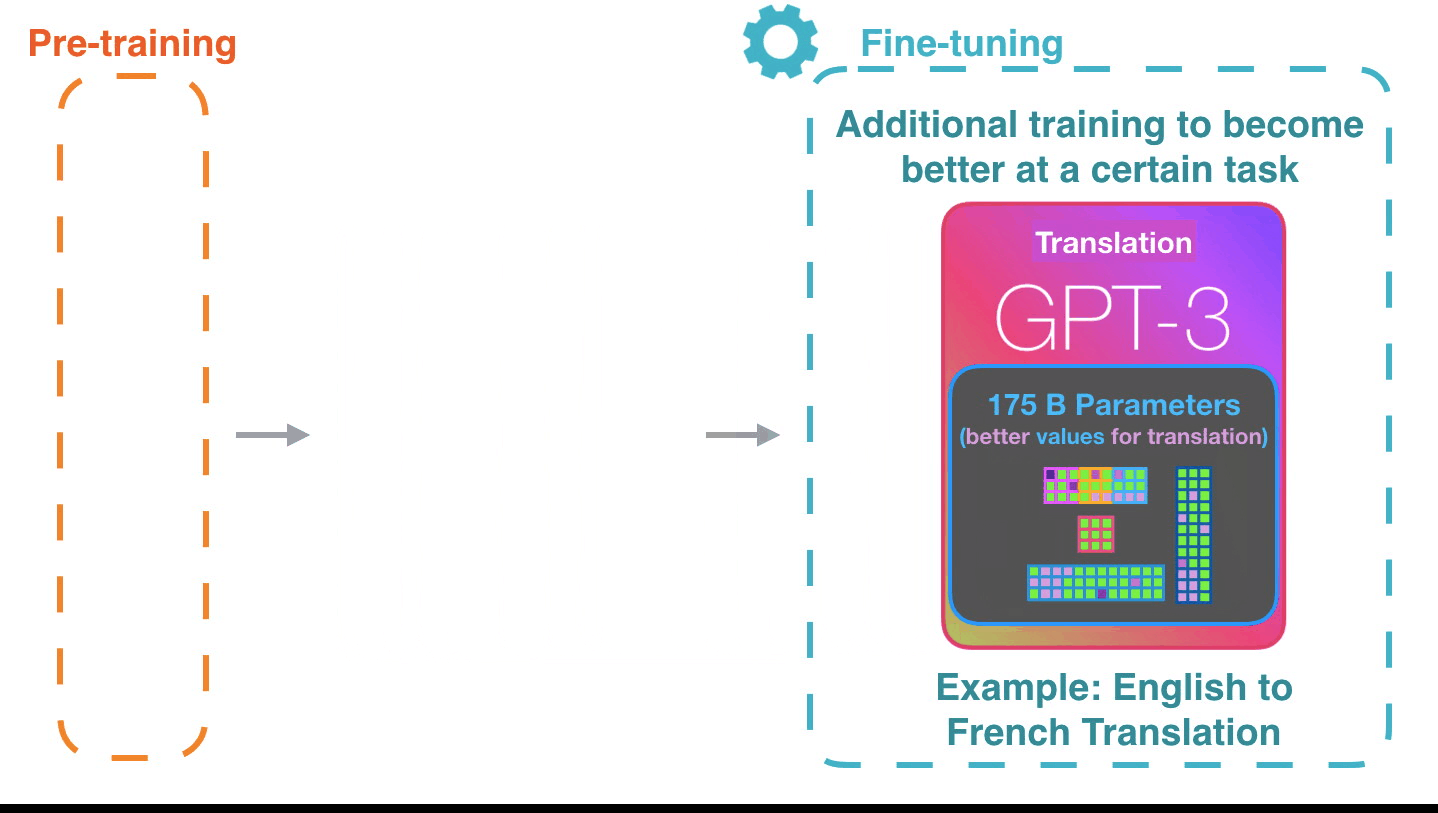
## MLOps
|
text-center |
shiki |
|
true |
true |
%s |
Bringing ideas to production 🚀
March 15th, 2024
::left::
::right::

layout: presenter photo: https://charlas.2023.es.pycon.org/media/avatars/blob_p6VtbO9.jpg
- 🇧🇷 → 🇧🇪: Brazilian @ Belgium
- 🤓 B.Sc. in Mechanical Engineering @PNW
- 👨🎓 M.Sc. in Artificial Intelligence @KUL
Professional Data & ML Engineer
Machine Learning Specialty
Terraform Associate
DAG Authoring & Airflow
SnowPro Core
Prefect Associate
- 🤪 Fun facts: 🐍, 🦀, 🐓
- 🫂 Python User Group Belgium
- 📣 Confs: 🇯🇵, 🇵🇱, 🇮🇪, 🇵🇹, 🇪🇸, 🇸🇪
- 🎙️ Datatopics Unplugged Podcast
- 🤖 Tech lead AI @




::left::
- Events company 📣
- No show prediction 🫥
- Record deduplication 👯♀️
- Recommend visitors and exhibitors 🤝
- PoC MVP Production 🚀
::right::
::left::

::right::
- Content moderation @ social media company 🤬
- NER @ clinical studies 🔎
- Q&A chatbots @ automotive industry 🏎️
- Energy consumption forecasting @ public sector 📈
- Network analysis @ accounting company 🕸️
::left::
- Finacial sector 💰
- Early customer lifetime value 🤑
- Pipeline migrations 🧑🔧
- Churn prediction 🫠
::right::


“pixel art angry face with symbols on mouth censoring profanity” - DALL·E 2
::left::
- You're the CEO of 10gag ( congrats! 🎉 )
- (Like 9gag, but better)
- (Like 9gag, but better)
- Things haven't been so good lately 🫣
- You have some trolls leaving nasty comments 🤬
- You have an idea! 💡
- You can probably detect these comments, and remove them from the platform
-
How well can we identify these comments using machine learning?
::right::

::left::
::right::
We are getting [value]{v-mark.highlight.yellow=1} from our models
::left::

::right::

::left::
- Accumulate predictions and run them together
- Schedule runs every hour/day/week/month
- Write the predictions to a table to a dashboard


::right::
- User does something
- This "something" triggers a (REST) API call
- Call return results/action

::bottom::
<style> img { @apply h-25 !important; } </style>When should we choose one over the other?
::right::

::left::
flowchart LR
subgraph API
direction TB
cloud("☁️") <--> phone("📱")
end
API --> batch("🍪")
API --> realtime("👟")
<iframe src="https://asciinema.org/a/646947/iframe?speed=5" p-5 w-full h-105/>

::left::
::right::
::bottom::
graph LR
bread("🥖") <--> bike("🚴♀️") <--> person("🥸")
“Latency is a [measurement]{v-mark.red="'+1'"} in Machine Learning to determine the performance of various models for a specific application. Latency refers to the [time taken to process one unit of data provided only one unit of data is processed at a time]{v-mark="{type:'highlight', color:'yellow', multiline:true, at:'+1'}"}.”
::left::
- Stable LM from Stability AI
"ChatGPT-like"
- Prompts:
Generate a list of the 10 most beautiful cities in the world.How can I tell apart female and male red cardinals?
rootsacademy-model-latency/
├── ...
├── common
│ ├── __init__.py
│ └── utils.py
├── pyproject.toml
└── scripts
├── local.py
└── remote.py::right::

<iframe src="https://asciinema.org/a/8PRQDcwFUTLXQ2WQYqczGV5IY/iframe?speed=2&idleTimeLimit=3" p-5 w-full h-105/>
::left::

::right::

::bottom::

::left::
- Cloud makes it easy to scale vertically
- Higher overhead to manage clusters (horizontal scaling)
- Vertical scaling has limits
- [Serverless machines]{.gradient-text.font-bold} can help optimize costs
- Horizontal scaling can be autoscaled
- Both may be cost efficient, depending on the setup

::right::

<iframe src="https://asciinema.org/a/x5zX5jFKYtFVzg0FZXL9lW9Mo/iframe?speed=3&idleTimeLimit=3" p-5 w-full h-105/>
::left::

::right::

::left::

<iframe bg-slate-50 p-2 w-full h-60 rounded shadow src="https://ggml.ai/" />
::right::

<iframe src="https://asciinema.org/a/iphbEPhRNdS01C2aupWDj5VMM/iframe?speed=2&idleTimeLimit=3" p-5 w-full h-115/>
“Edge machine learning (edge ML) is the process of running machine learning algorithms on computing devices [at the periphery of a network]{v-mark="{type:'highlight', color:'yellow', multiline:true, at:'+1'}"} to make decisions and predictions as close as possible to the originating source of data.”
For limited resources and extremely low latencies, you may need to [look outside ML]{.gradient-text}
::left::
<iframe w-full h-85 rounded shadow src="https://arxiv.org/pdf/2212.09410.pdf" />::right::



::left::

{kind=link}
{kind=link}
::right::
flowchart LR
camera("📸") --> ruler("📐")
ruler --> pos("👍")
ruler --> neg("👎")
neg --> brain("🧠")
brain --> _pos("👍")
brain --> _neg1("👎")
::right::
::left::
👨💼 "How long will it take to go though 100 posts? How can we make it faster?"
👷♀️ "How can we make sure the model scales?"
👷♂️ "What packages did you use?"
😡 "Why is it removing my posts?"
👩🔬 "What models did you already try?"
🕵️ "What data was used to train this model?"
::bottom::
[MLOps decreases the burden of deploying ML systems by establishing best practices]{v-mark.highlight.yellow=8}
“At this point, everybody does what they like, there is [little to no standardisation]{v-mark.red=1}. Since there are little to [no best practices]{v-mark.box.yellow=1}, the current platform contains the largest common denominator of a lot of heterogeneous projects. This causes a lot of [burden in maintaining]{v-mark.circle.pink=1} these projects”
“For quite some time, the focus was on more traditional Business Intelligence and Data Engineering. More recently we have seen the focus shifted more towards Advanced Analytics in the form of some scattered initiatives and products, which in turn lead to [little success]{v-mark.highlight.yellow=2} on these.”
“While I love our Data Science team, the [code they write is not at all up to standards]{v-mark.box.red=3} in comparison to what we normally push into production. This puts a [heavy burden]{v-mark.circle.yellow=3} on the Data Engineering team to [rewrite and refactor]{v-mark.highlight.yellow=3} this. At the same time the Data Science team is often [unhappy]{v-mark.blue=3}, because this refactoring process tends to introduce [mistakes or misunderstandings]{v-mark.highlight.cyan=3}.”
::left::
- Experimentation
- Data exploration
- Modelling
- Hyperparameter tuning
- Evaluation
::right::
- Infrastructure
- Scalability
- Reproducibility
- Monitoring/Alerting
- Automation
::bottom::
::left::
- Iterative-Incremental Development
- [Automation]{v-mark.blue="'+1'"}
- [Continuous Deployment]{v-mark.blue="'+1'"}
- [Versioning]{v-mark.blue="'+1'"}
- [Testing]{v-mark.blue="'+1'"}
- [Reproducibility]{v-mark.blue="'+1'" v-mark.box.red="'+2'"}
- Monitoring
::right::
+ Model
+ Features
+ Data
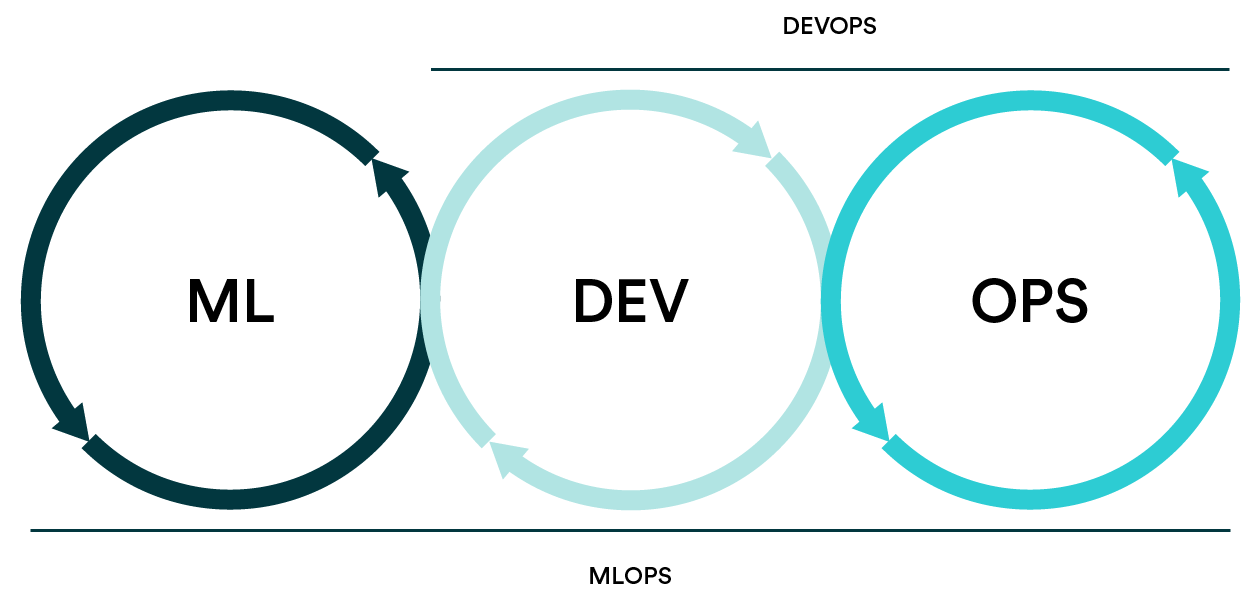
"[...] By codifying these practices, we hope to accelerate the adoption of ML/AI in software systems and fast delivery of intelligent software. In the following, we describe a set of important concepts in MLOps such as [Iterative-Incremental Development, Automation, Continuous Deployment, Versioning, Testing, Reproducibility, and Monitoring]{v-mark="{type:'highlight', color:'yellow', multiline:true, at:2}"}."
“The [level]{v-mark.circle.blue=1} of automation of these steps defines the maturity of the ML process, which [reflects the velocity of training new models given new data or training new models given new implementations]{v-mark="{type:'highlight', color:'yellow', multiline:true, at:2}"}. The following sections describe three levels of MLOps, starting from the most common level, which involves no automation, up to automating both ML and CI/CD pipelines.”
[> “In theory, theory and practice are the same. In practice, they are not.” - Einstein]{v-click}
<iframe src="https://arxiv.org/ftp/arxiv/papers/2205/2205.02302.pdf" w-full h-95 rounded shadow-lg v-click/>For each of these challenges, which ones are related to [ML]{v-mark.highlight.red=1} or [Ops]{v-mark.highlight.cyan=1} ?
::left::
- [Models and experiments are not properly tracked]{v-mark.highlight.cyan=2}
- [Model decay]{v-mark.highlight.red=3}
- [Changing business objectives]{v-mark.highlight.red=4}
- [Models monitoring and (re)trainining]{v-mark.highlight.cyan=5}
- [Data quality]{v-mark.highlight.red=6}
- [Consistent project structure]{v-mark.highlight.cyan=7}
- [Data availability]{v-mark.highlight.red=8}
::right::
- [Code and dependencies tracking]{v-mark.highlight.cyan=9}
- [Auditability and regulations - reproducibility and explainability]{v-mark.highlight.cyan=10}
- [Wrong initial assumptions (problem definition)]{v-mark.highlight.red=11}
- [Locality of the data (distributional shift)]{v-mark.highlight.red=12}
- [Recreate model artifacts]{v-mark.highlight.cyan=13}
- [Deploy model systems(not just one off solutions)]{v-mark.highlight.cyan=14}
idea --> poc --> mvp --> prod
```mermaid
%%{init: {"flowchart": {"htmlLabels": false}} }%%
flowchart LR
eda["`Exploratory Data Analysis 🔎`"]
model["`Modeling 📦`"]
eval["`Evaluation ⚖️`"]
deploy["`Deployment 🏗️`"]
monitor["`Monitoring 👀`"]
eval .-> model
eval .-> eda
eda --> model --> eval --> deploy --> monitor
 {.absolute .top-0 .scale-110}
{.absolute .top-0 .scale-110}
::left::
- Data versioning 🚀
- Reproducing models and scores
- Feature engineering 📦
- Version code + artifacts
- Model training 🌱
- Track experiments (models hyperparameters, etc.)
- Use seeds
- Quality assurance 🔍
- Unit/integration tests
- Statistical tests
- Stability tests
- GenAI tests? - Validation, self reflection, etc.
- Prepare for deployment 🏗️
- Packaging and containerizing!
::right::


- How to deploy models depends on whether you have a [batch or real time]{v-mark.box.blue=1} use case
- It's important to minimize [latency]{v-mark="{at:2, color:'red', brackets:['bottom'], type: 'bracket'}"} in real time use cases
- Latency can be reduced by [scaling resources or reducing computational needs]{v-mark.highlight.yellow=3}
- MLOps is a [set of principles]{v-mark.red=4} reduces the burden of deploying and maintaining models
- Unless you're doing research, the [value]{v-mark.box.yellow=5} of models only come after they have been [deployed]{v-mark.circle.green=5}
::bottom::
[As ML gets easier and easier to do, MLOps and software engineering skills becomes increasingly important]{.gradient-text}
