The Jazz Trio Database is a dataset composed of about 45 hours of jazz performances annotated by an automated signal processing pipeline.
The database contains about 45 hours of audio recorded between 1947–2015 with associated timing annotations and MIDI (piano only). The timing annotations were generated by an automated signal processing pipeline: source separation models are applied to obtain isolated stems from every instrument in each recording, onsets are tracked in these stems, and these onsets are matched with the nearest quarter note pulse tracked in the audio mixture. Over 10% of the dataset also has corresponding ground truth annotations (onsets and beats), created manually by the research team. These annotations were used to set the parameters of our detection algorithms, to maximize the correspondence between human- and algorithm-detected onsets (see references\parameter_optimisation\).
Audio recordings are not stored directly in this repository. Instead, when you run the script to build the dataset, these files will be downloaded automatically from an official YouTube source (see the Download section, below). Note that, occasionally, individual YouTube recordings may be taken down: these tracks will be skipped when building the dataset, but please report any issues [here](mailto:[email protected]?subject=CJD Missing YouTube link) so that working links can be added in these cases.
Below is an example of what the timing data looks like:
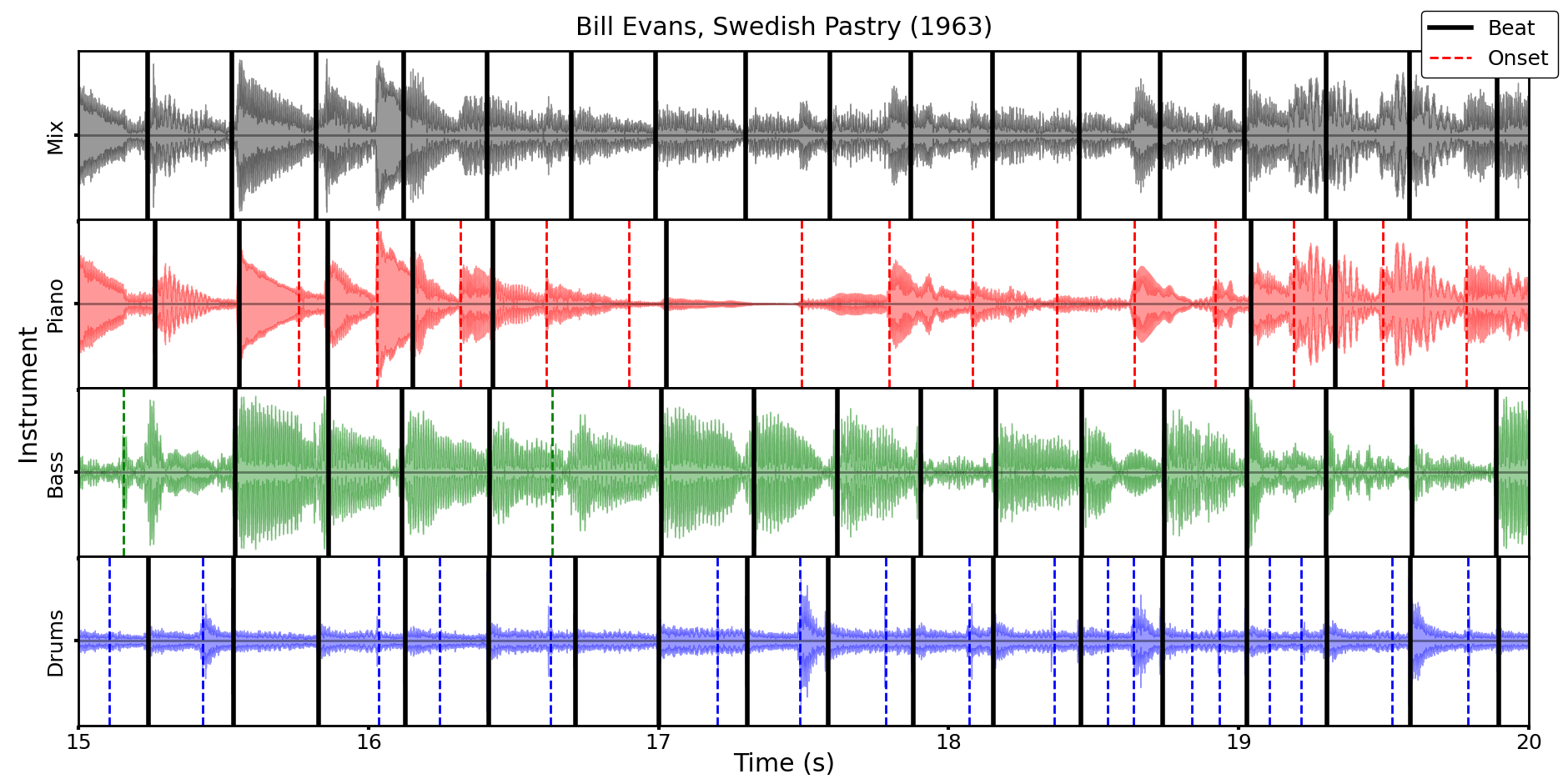
The Jazz Trio Database is provided as a .zip file containing the onset and beat annotations in .csv format, piano MIDI in .mid format, and metadata in .json format. The source code for building these onsets is also available publicly. To download the database, navigate to Releases and download the most recent .zip file.
The metadata files contain the following fields for every recording:
| Field | Type | Description |
|---|---|---|
track_name |
str | Title of the recording |
album_name |
str | Title of the earliest album released that contains the track |
recording_year |
int | Year of recording |
in_30_corpus |
bool | Whether the track is contained in the JTD-300 subset of recordings (see paper) |
channel_overrides |
dict | Key-value pairs relating to panning: piano: l means the piano is panned to the left channel |
mbz_id |
str | Unique ID assigned to the track on MusicBrainz |
time_signature |
int | The number of quarter note beats per measure for the track |
first_downbeat |
int | The first clear quarter note downbeat in the track |
rating_audio |
int | Subjective rating (1–3, 3 = best) of source-separation quality |
rating_detection |
int | Subjective rating of onset detection quality |
links |
dict | YouTube URL for the recording |
excerpt_duration |
str | Duration of recording, in Minutes:Seconds format |
timestamps |
dict | Start and end timestamps for the piano solo in the recording |
musicians |
dict | Key-value pairs of the musicians included in the recording |
fname |
str | Audio filename |
Hit the button to process tracks online!
To process a piano trio recording using our pipeline, you can use a command line interface to run the code in src/process.py. For example, to process 30 seconds of audio from Chick Corea's Akoustic Band 'Spain':
git clone https://github.com/HuwCheston/Jazz-Trio-Database.git
cd Jazz-Trio-Database
python -m venv venv
call venv/Scripts/activate.bat # Windows
source venv/bin/activate # Linux/OSX
pip install -r requirements.txt
bash postBuild # Linux/OSX only: download pretrained models to prevent having to do this on first run
python src/process.py -i "https://www.youtube.com/watch?v=BguWLXMARHk" --begin "03:00" --end "03:30"
This will create a new folder in the root directory of the repository: source audio is stored in /data, annotations in /annotations, and extracted features in /outputs. By default, the script will use the parameter settings described in Cheston, Schlichting, Cross, & Harrison (2024a). This can be changed by passing -p/--params, followed by the name of a folder (inside references/parameter_optimisation) containing a converged_parameters.json file.
The script will also use a set of default parameters for the given track (e.g. time signature). To override these, pass in the -j/--json argument, followed by a path to a .json file following the format outlined in the metadata table above.
The dataset is made available under the MIT License. Please note that your use of the audio files linked to on YouTube is not covered by the terms of this license.
If you use the Jazz Trio Database in your work, please cite the paper where it was introduced:
@misc{
title = {Jazz Trio Database: Automated Timing Annotation of Jazz Piano Trio Recordings Processed Using Audio Source Separation},
publisher = {Transactions of the International Society for Music Information Retrieval},
author = {Cheston, Huw and Schlichting, Joshua L and Cross, Ian and Harrison, Peter M C},
doi = {forthcoming},
year = {2024},
}
Creation of the database has resulted in the following published research outputs:
- Cheston, H., Schlichting, J. L., Cross, I., & Harrison, P. M. C. (2024a, forthcoming). Jazz Trio Database: Automated Annotation of Jazz Piano Trio Recordings Processed Using Audio Source Separation. Transactions of the International Society for Music Information Retrieval. preprint: https://doi.org/10.31234/osf.io/jyqp3.
- Cheston, H., Schlichting, J. L., Cross, I., & Harrison, P. M. C. (2024b). Rhythmic Qualities of Jazz Improvisation Predict Performer Identity and Style in Source-Separated Audio Recordings [Preprint]. PsyArXiv. https://doi.org/10.31234/osf.io/txy2f.
- Cheston, H., Cross, I., & Harrison, P. M. C. (2023). An Automated Pipeline for Characterizing Timing in Jazz Trios. Proceedings of the DMRN+18 Digital Music Research Network. Digital Music Research Network, Queen Mary University of London, London, United Kingdom.