This is a Basic Project that will help one understand Unsupervised Learning in a Brief way. Project-wise learning is one of the most effective ways to learn anything.
![]() Author: @Srayoshi-Mirza
Author: @Srayoshi-Mirza
Customer segmentation is the process of dividing a customer base into groups of individuals who are similar in specific ways relevant to marketing, such as age, gender, interests, spending behavior, and more. The goal of customer segmentation is to understand better and meet the unique needs of different customer groups, allowing businesses to tailor their marketing strategies, product offerings, and customer experiences for maximum effectiveness.
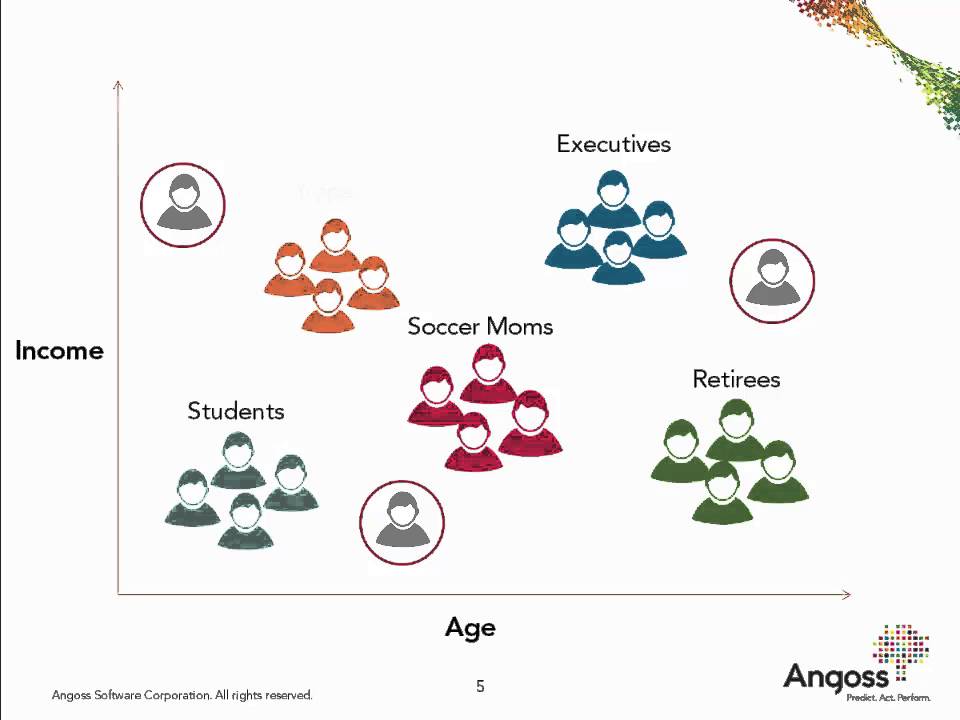
Unsupervised learning is a type of machine learning where the algorithm is presented with a dataset without labeled responses or targets. Unlike supervised learning, where the model is trained on a dataset with explicit labels, unsupervised learning involves extracting patterns, structures, or relationships inherent in the data without predefined categories. Common techniques in unsupervised learning include clustering, where similar data points are grouped, and dimensionality reduction, which aims to reduce the complexity of the dataset while preserving essential features. Unsupervised learning is beneficial for discovering hidden patterns and gaining insights into the intrinsic properties of the data.

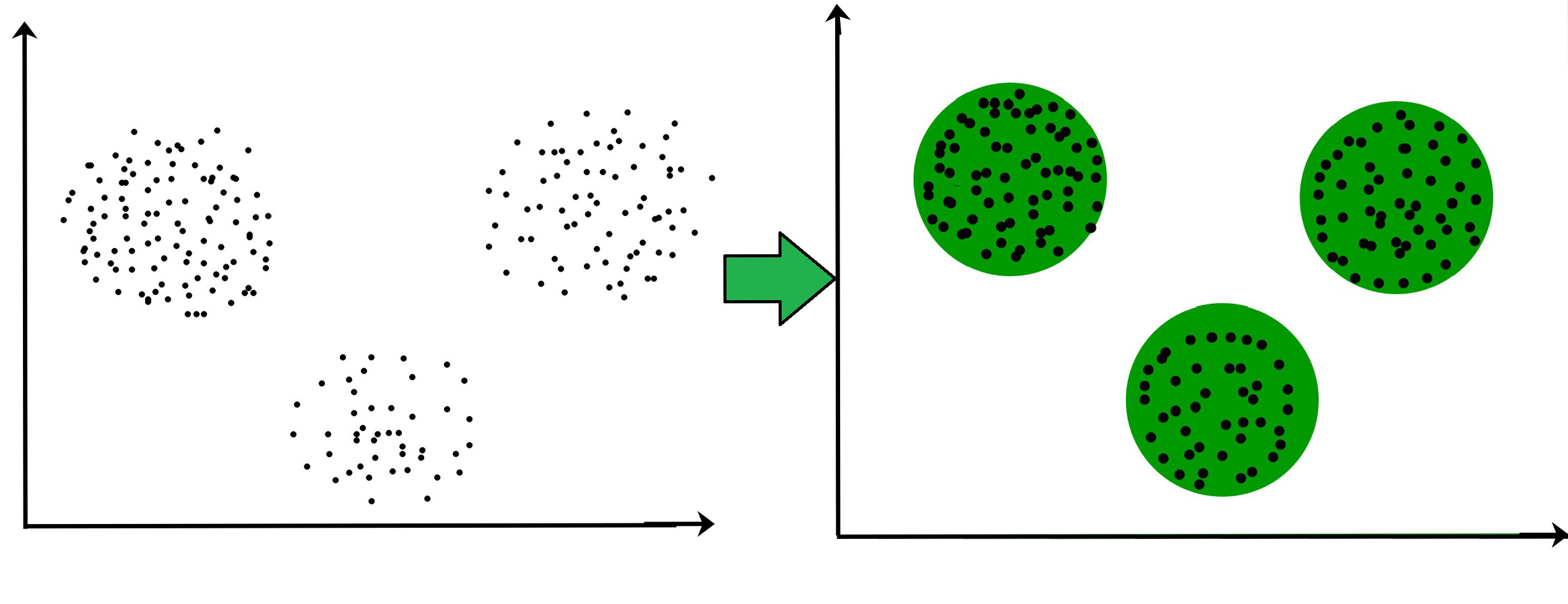
Clustering is a process of grouping similar objects; i.e., to partition unlabeled examples into disjoint subsets of clusters, such that:
1. Examples within a cluster are similar (in this case, we speak of high intraclass similarity).
2. Examples in different clusters are different (in this case, we speak of low interclass similarity).
Two kinds of inputs can be used for grouping:
- in similarity-based clustering, the input to the algorithm is an n × n dissimilarity matrix or distance matrix;
- in feature-based clustering, the input to the algorithm is an n × D feature matrix or design matrix, where n is the number of examples in the dataset and D is the dimensionality of each sample.
Similarity-based clustering allows easy inclusion of domain-specific similarity, while feature-based clustering has the advantage that it applies to potentially noisy data.
Dataset Link: Ecommerce Customer Data
This dataset contains data from customers from an E-commerce platform. (2022-01-19) Can use this data to predict the Yearly Amount Spent based on customer features
Columns:
- Address
- Avatar
- Time on App
- Time on Website
- Length of Membership
- Yearly Amount Spent
Title: Ecommerce Customer Data
Author: Mason Greenwood, Mason Greenwood
The primary objective of this project is to segment customers based on relevant features, uncovering meaningful insights that can guide business strategies.
Utilized
- K-Means clustering
- Hierarchical clustering algorithms
- Top-Down
- Bottom-Up to identify and group similar customers.
- Conducted data preprocessing, including handling missing values, encoding categorical variables, and scaling features.

- Selected relevant features for clustering.
- Time on App
- Time on Website
- Length of Membership
- Yearly Amount Spent
- Employed visualizations such as scatter plots to represent clusters.



- Utilized cluster characteristics plots to provide an overview of each cluster.


Evaluated clustering quality using metrics like silhouette score, examining cluster characteristics, and analyzing feature importance.
- Identified distinct customer segments with varying spending patterns and engagement levels.
- Explored the characteristics and behavior of each cluster.
- Examined the distribution of data points within clusters.
- Compared results with K-Means clustering, highlighting differences and similarities.
- Presented insights into cluster sizes and their significance.
- Discussed the implications of the identified clusters on business strategies.
- Explored the importance of features in distinguishing clusters.
- Identified key features contributing significantly to the separation of clusters.

- Compared the performance of K-Means, Top-Down Hierarchical, and Bottom-Up Hierarchical clustering.
- Discussed the strengths and weaknesses of each method.

- Interpreted the meaning of each cluster in practical terms.



- Linked clusters to potential business actions, enabling targeted strategies for different segments.
Acknowledged limitations in the current approach, such as potential bias or data constraints. Suggested future directions, including exploring additional features or refining clustering algorithms.