Make "async ValueTask/ValueTask<T>" methods ammortized allocation-free #26310
Conversation
|
What do we expect the performance gains from this to be - for primary perf metrics like requests per second for something real looking? (I understand that this will reduce the number of GCs by moving the cost elsewhere.) |
Don't know yet. I'm hoping by putting this up as a draft folks will try it out :) I'm also going to try it on a few workloads. I won't be merging it until it proves valuable. |
...ystem.Private.CoreLib/shared/System/Runtime/CompilerServices/AsyncValueTaskMethodBuilderT.cs
Outdated
Show resolved
Hide resolved
|
Will give it a whirl :) |
|
Isn't very happy |
What is this running? |
Just trying to debug into it as the stack trace clearly isn't very helpful :) |
I say it's better to make this change sooner rather than later. I like that this change might teach people the hard way not to await the same ValueTask multiple times since it will no longer just Pipes and other IValueTaskSource-based ValueTasks that break. Do you expect there will be any common workloads where pooling the boxes hurts perf? |
It's hard to say. Using pooling is based on the assumption that the overheads associated with pooling (e.g. synchronization to access the pool, any cache effects that come from using the pool, etc.) are less than the overheads associated with allocation+GC. That is not always the case, but it's also hard to predict. There's also the fact that this is changing the underlying implementation, so it's not just pooling vs non-pooling, but ValueTask wrapping Task vs wrapping IValueTaskSource, different code paths being taken internally, different synchronization used to hook up a continuation, etc. Some of that is just tuning, but some of it will be trade-offs as well. In theory this approach could have less overhead even if pooling weren't used at all (just using a custom IValueTaskSource) because it doesn't need to accomodate things like multiple continuations, but we're also talking minutia at that point. In the end, I'll want us to vet this on real workloads that demonstrate real value before moving ahead with it. |
|
@mgravell has a pretty interesting library that does something very similar to this |
|
Revisiting https://github.com/dotnet/coreclr/issues/21612 again 😉 Since So rather than However that's not too important 😄 |
|
Issue I'm having I think is in websockets; as its specifically commented about it https://github.com/dotnet/corefx/blob/ba9f27788bd99a29e5d832531f0ee86d8eae4959/src/System.Net.WebSockets/src/System/Net/WebSockets/ManagedWebSocket.netcoreapp.cs#L30-L31 None of the other ValueTasks seem to be having issues |
Yup, I wrote both that code and comment :) Shame on me. Will change it. |
|
@mburbea I would be genuinely delighted if I could nuke that lib in entirety because the feature has been implemented in the core lib by folks who know better than me what they're doing. |
|
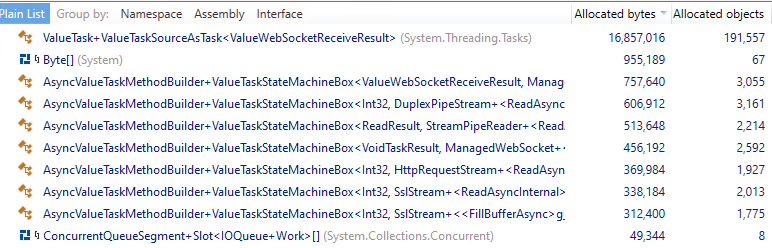
256 websocket connections ~30sec Pre Post Might still want to do "Amortize WebSocket.EnsureBufferContainsAsync" dotnet/corefx#39455 not sure why its not really effected by this change; however it does address the harder to amortize async methods. Will do some benchmarks |


Oh, simpler explanation: private async Task EnsureBufferContainsAsync;-) |
|
Yep, changing entirely fixes it |

|
I'm liking this very much. Even with its low(ish) pool limit the allocation growth is low 200 websocket connections ~30sec
1000 websocket connections ~30sec
And the cost for renting and returning boxes seems fairly minimal |
Thanks. Does it have a measurable impact on your throughout? |
|
The change in before and after allocations is huge 😄 1000 websocket connections ~30sec Pre: 1.36M objects allocated (245MB)
Post: 209K objects allocated (20MB)
|

Yes(ish); unfortunately (or fortunately), it moves it into a realm beyond what I can load test maximums accurately with my current setup as I can't generate enough load. Its also highlighted some other hot spots in our own code. While I can't currently quantify that (though will look into it more); more interestingly; it also means for the same number of GCs and RAM usage I can pack the containers at least x4 tighter when they aren't under maximum load. |
|
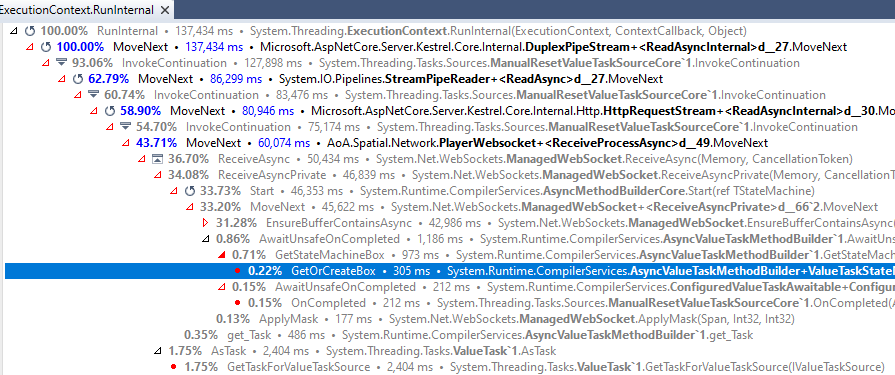
The overhead of GetOrCapture is less than capturing the ExecutionContext
Well some are more than others; but is a fairly insignificant cost
ReturnBox is a little more; but fairly small
|


|
@mgravell are you in a position to give this a try for your workloads? Note it only applies to async ValueTask and ValueTask (not async Task) |
Are these single-threaded microbenchmarks a good proxy for what happens in the real workloads? I have whipped a random multi-threaded one https://gist.github.com/jkotas/776a7609f8beaaa639230caa76c73813. The results I am getting:
Full Results``` D:\coreclr\bin\Product>set COMPlus_gcServer=1 D:\coreclr\bin\Product>baseline\CoreRun.exe stress.exe D:\coreclr\bin\Product>new\CoreRun.exe stress.exe |
|
Similar caches were source of troubles in the unmanaged threadpool in the past. We ended up with per-processor caches, but they are still sub-optimal. The small memory blocks will lose their affinity to the right core over time and so one ends up with false sharing or cross-NUMA node memory access. The GC allocated memory avoids these issues. Having said this, I am fine with experimenting with this to see whether somebody can demonstrate measurable throughput improvement thanks to the caching. |
If there is a workload that shows measurable throughput improvement, I would like the GC team to take a look at the GC traces to validate that it is not hitting a GC tuning bug. |
|
Another interesting metric to look at is code size. Benchmark: https://gist.githubusercontent.com/jkotas/c3913ac6a98b3474b888926aa9066dd6/raw/95c548546d3e7d183e028348a96a50181c1546ed/manytasks.cs. Native code size bytes from perfview JIT stats: baseline: 2,603,033 bytes |
That case should be unaffected by parallelism. If you see opportunities in this PR to address that, I'd love to hear about it. I also put your example into Benchmark.NET form: using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Diagnosers;
using BenchmarkDotNet.Running;
using System;
using System.Threading.Tasks;
[MemoryDiagnoser]
public class Program
{
static void Main(string[] args) => BenchmarkSwitcher.FromAssemblies(new[] { typeof(Program).Assembly }).Run(args);
[Benchmark]
public void Parallel()
{
var tasks = new Task[Environment.ProcessorCount * 4];
for (int i = 0; i < tasks.Length; i++) tasks[i] = Work();
Task.WaitAll(tasks);
}
static async ValueTask<int> Step(int i)
{
if (i >= 999) await Task.Delay(1);
else await Task.Yield();
return i + 1;
}
static async Task Work()
{
var r = new Random();
for (int i = 0; i < 100000; i++)
{
await Step(r.Next(1000));
}
}
}and I get:
Maybe there's a machine-specific aspect to it? (There's also both randomness and "saturate the machine" parallelism here, so there's going to be variability.) Note that the goal is for there to be 0 perf impact on an example like yours when the cache is off: it's meant to use exactly the same infrastructure as is used today with as little ceremony as we can muster to enable switching on the cache optionally, though there are a few tweaks to try to improve ValueTask perf even in the case where the cache is off. Also note that a large portion of the time spent in your example is in the Task.Delay(1), which on Windows is going to incur an ~15ms delay. If I delete that part, I get:
My machine isn't as quiet as I'd like for a parallelism test, but I just ran it three times (without the Task.Delay, which dominates) and got:
Putting the Task.Delay back in I again saw basically no difference (in throughput... obviously the allocation is much different):
There's a layer of helpers this is going through in order to enable the opt-in switch. If we were to switch to an always-on model, I'd expect this to go away.
Every There's another option as well. Right now the switch flips between doing exactly what we do today (async completions are backed by Task instances) and using the cache (async completions are backed by pooled IValueTaskSource instances). I could also make it so that the switch only controls whether the cache is used, i.e. always use the IValueTaskSource instances, but if the switch is off, behave as if no instances could ever be retrieved from the cache (and don't try to return anything to it). The upside of that is
I'm having trouble rationalizing that with your stats and comments about GC tuning, as it sounds like your opinion is that a) this shouldn't be necessary, and b) if it is it's because of a GC perf bug that should be fixed... and then see (a). 😉 Is your preference I just close this PR? |
|
The occasional I know there is a lot of interest in building caches like these because of single-minded focus on GC allocations. I would like to see a more data on whether they are worth it. It is why I have said that I am fine with experimenting with this. This interest in building caches like these won't go away until we have this data. Personally, I believe that this cache should not be needed as long as the GC is working properly (and the cache likely hurts performance on average in real workloads). But I do not have data to prove it. |
|
In netcoreapp3.0
For a very light load (0% CPU), they allocate 127MB every 1.5minutes and cause a GC
With the app stabilising around 170MB working set, 420MB Commit size (though still creeping up slowly)
Will report back changes, in this PR |



|
Distracted by trying to find out what all the native allocations are |
|
Raised question on the the 12MB of Jit allocations hanging around: https://github.com/dotnet/coreclr/issues/27357 syncblocks and threads (and threadstatics for those threads) it looks like later in the execution
|


| private static int GetPoolAsyncValueTasksLimitValue() => | ||
| int.TryParse(Environment.GetEnvironmentVariable("DOTNET_SYSTEM_THREADING_POOLASYNCVALUETASKSLIMIT"), out int result) && result > 0 ? | ||
| result : | ||
| Environment.ProcessorCount * 4; // arbitrary default value |
There was a problem hiding this comment.
Seems a bit low
suggestion~~ ~~ Environment.ProcessorCount * 32; // arbitrary default value~~ ~~
There was a problem hiding this comment.
Nvm, have same allocation profile with 4 and 32.
|
Roughly same period with same load
97MB working set, 355MB Commit size though it keeps going up (likely due to the
|



|
High load (~1.5 mins 4 cores 8 HT)
|




|
Assuming the With this change off, running under load I quickly hit 1GB working set (less than 30 secs):
after which it doesn't increase but will start cycling through GCs. Can cap it lower with the new options in .NET 3.0+ but that will mean it GCs faster. With
Both have around ~275MB in actual use
But the original has 1GB allocated to the program and is incurring continuous GCs; the other aside from the point at the top* only has 291MB allocated to the program to do it and has no GCs; and yet both are doing heavy async network work. The big win here is the ability not just to reduce GC allocations but to move to a zero alloc pauseless stable state; while using the standard framework methods, were the GC never needs to run and the working set remains small. One aspect of this is it allows tighter packing of processes/containers etc. Another aspect is: like intrinsics it opens up a new set of problems for .NET Core to be applicable for (not disrespecting the amazing work the GC does); as there are areas where people reject the idea of a GC needing to periodically run. |

|
Are you able to measure peak RPS that your server can handle? If yes, do the extra GCs make measurable impact on the peak RPS (GC limited to 300MB vs. this thing)?
This looks like a very large limit. It means you can easily have 50kB - 100kB in caches for each ValueTask used in your program.
These people should use Rust. .NET is not going to be a success story for them. |
|
@benaadams what kind of pause targets do your workloads have? How rare do pauses have to be? Essentially zero? Games have a lot of trouble with GC pauses as well. Attaining no pauses requires an awkward coding style. A 60Hz framerate means a 16ms budget per frame. I understand you need a small heap to survive a single G0 collection with this. My main point: Maybe we could best solve this pause issue with low-pause GC features instead of running after every possible source of garbage. G2 pauses are (in my experience) very bearable these days because it's all background. I have a production web site with a 1GB heap. I see 10ms G2 pauses but I see 100ms G0 and G1 pauses. So those have become more of a problem now. @Maoni0 said something similar in her recent talk. @benaadams would you be satisfied if the GC was able to cap all pauses at say 10ms? Would there still be a need to limit their frequency? |
Retested under high load, end up with same allocation profile with
Its not very awkward anymore with .NET Core 3.0 and C#8; certainly much less awkward than with rust's borrow checker. The aim is not for the purity of no allocations, which is indeed more problem than its worth, but long sustained periods of no allocations; and this is also the approach many games take where when and where allocations happen is constrained and controlled. This works quite well in .NET Core 3.0; except for async calls; which is intensely awkward e.g. see code changes in dotnet/corefx#39455, dotnet/aspnetcore#11942 which are fairly straightforward async methods and all the methods in the BCL need to be changed for this to work or require re-implementation externally to make non-allocating versions. Async is also problematic as the statemachines are sat on for a while; in that they generally take some time and form long chains of statemachines, so when one propergates a GC generation it is many. The advantage of this change is no special code is required by the implementer and it works for their methods too.
That would definitely be a useful tool; much like |
Will investigate further
Current limit looks ok
Could drop the caches on a GC as per Gen2GcCallback? So infrequent async statemachines don't get cached forever? |
Could guard it with something that's dropped from R2R like |
Today `async ValueTask/ValueTask<T>` methods use builders that special-case the synchronously completing case (to just return a `default(ValueTask)` or `new ValueTask<T>(result))` but defer to the equivalent of `async Task/Task<T>` for when the operation completes asynchronously. This, however, doesn't take advantage of the fact that value tasks can wrap arbitrary `IValueTaskSource/IValueTaskSource<T>` implementations. This commit gives `AsyncValueTaskMethodBuilder` and `AsyncValueTaskMethodBuilder<T>` the ability to use pooled `IValueTaskSource/IValueTaskSource<T>` instances, such that calls to an `async ValueTask/ValueTask<T>` method incur 0 allocations (ammortized) as long as there's a cached object available. Currently the pooling is behind a feature flag, requiring opt-in via the DOTNET_SYSTEM_THREADING_POOLASYNCVALUETASKS environment variable (setting it to "true" or "1"). This is done for a few reasons: - There's a breaking change here, in that while we say/document that `ValueTask/ValueTask<T>`s are more limited in what they can be used for, nothing in the implementation actually stops a `ValueTask` that was wrapping a `Task` from being used as permissively as `Task`, e.g. if you were to `await` such a `ValueTask` multiple times, it would happen to work, even though we say "never do that". This change means that anyone who was relying on such undocumented behaviors will now be broken. I think this is a reasonable thing to do in a major release, but I also want feedback and a lot of runway on it. - Policy around pooling. Pooling is always a difficult thing to tune. Right now I've chosen a policy that limits the number of pooled objects per state machine type to an arbitrary multiple of the processor count, and that tries to strike a balance between contention and garbage by using a spin lock and if there's any contention while trying to get or return a pooled object, the cache is ignored. We will need to think hard about what policy to use here. It's also possible it could be tuned per state machine, e.g. by having an attribute that's looked up via reflection when creating the cache for a state machine, but that'll add a lot of first-access overhead to any `async ValueTask/ValueTask<T>` method. For now, it's tunable via the `DOTNET_SYSTEM_THREADING_POOLASYNCVALUETASKSLIMIT` environment variable, which may be set to the maximum number of pooled objects desired per state machine. - Performance validation. Preliminary numbers show that this accomplishes its goal, having on-par throughput with the current implementation but with significantly less allocation. That needs to be validated at scale and across a variety of workloads. - Diagnostics. There are several diagnostics-related abilities available for `async Task/Task<T>` methods that are not included here when using `async ValueTask/ValueTask<T>` when pooling. We need to evaluate these (e.g. tracing) and determine which pieces need to be enabled and which we're fine omitting. Before shipping .NET 5, we could choose to flip the polarity of the switch (making it opt-out rather than opt-in), remove the fallback altogether and just have it be always on, or revert this change, all based on experimentation and data we receive between now and then.
04fc18f
to
c85cc72
Compare
Maybe, but that would make certain aspects of this harder and potentially more expensive. Right now I get away with things like Unsafe.As because I know everything will be either type A or type B, per the readonly static that never changes. A fallback like I think you're suggesting would mean I could no longer trust that and would need to come up with an alternative. It might be reasonable to still do something like you suggest, but use it as a mechanism to impact cache size, e.g. only start caching boxes after N calls to the method. That would help avoid heap object bloat for rarely used methods, but it wouldn't help with the aforementioned code size issues (and could be addressed in other ways, like dropping all boxes on gen2 gcs). The best thing we can do for code size I think is decide to either delete this change or delete the fallback, so that we're not paying double the code for every such method. |
|
Given the feedback, the desire for more data, and the agreement that this is a reasonable way to get it and experiment more, I'm going to go ahead and merge this. I'll open an issue up track follow-ups for .NET 5. Thanks. |
Today
async ValueTask/ValueTask<T>methods use builders that special-case the synchronously completing case (to just return adefault(ValueTask)ornew ValueTask<T>(result)) but defer to the equivalent ofasync Task/Task<T>for when the operation completes asynchronously. This, however, doesn't take advantage of the fact that value tasks can wrap arbitraryIValueTaskSource/IValueTaskSource<T>implementations.I've had this sitting on the shelf for a while, but finally cleaned it up. The first three commits here are just moving around existing code. The last two commits are the meat of this change. This changes
AsyncValueTaskMethodBuilderandAsyncValueTaskMethodBuilder<T>to use pooledIValueTaskSource/IValueTaskSource<T>instances, such that calls to anasync ValueTask/ValueTask<T>method incur 0 allocations as long as there's a cached object available.I've marked this as a draft and work-in-progress for a few reasons:
ValueTask/ValueTask<T>s are more limited in what they can be used for, nothing in the implementation actually stops aValueTaskthat was wrapping aTaskfrom being used as permissively asTask, e.g. if you were to await such aValueTaskmultiple times, it would happen to work, even though we say "never do that". This change means that anyone who was relying on such undocumented behaviors will now be broken. I think this is a reasonable thing to do in a major release, but I also want feedback and a lot of runway on it. There's the potential to make it opt-in (or opt-out) as well, but that will also non-trivially complicate the implementation.async ValueTask/ValueTask<T>method.cc: @kouvel, @tarekgh, @benaadams